Element identification is all about setting up a combination of attributes for an Element, so that it can be uniquely identified on the screen, during automated test execution.
An element may be uniquely identified using multiple combinations of attributes. In addition, you may also include attributes from neighborhood nodes for identifying a given element. Not all attributes may be equally suitable from a long term maintenance and change-management point of view. And some times, you may need to alter the value of an attribute to use Regular Expression pattern, to achieve stability.
Here are some pointers to help you with setting up a stable element identification. These are just general suggestions, and there may always be exceptions in a specific environment. Based on the grasp on these concepts, you may develop a strategy applicable for your needs.
Attributes with numeric values
In general, any attribute whose value includes random numeric digits may not be a suitable one to use.
Take an example below. When you use the attribute id as part of the Selector, it seems to get a perfect unique ID. But this value (2663:0) may not always stay the same and this value does not seem to have any functionally identifiable meaning. Application developer may change it in future or it may be dynamically generated based on various application conditions.
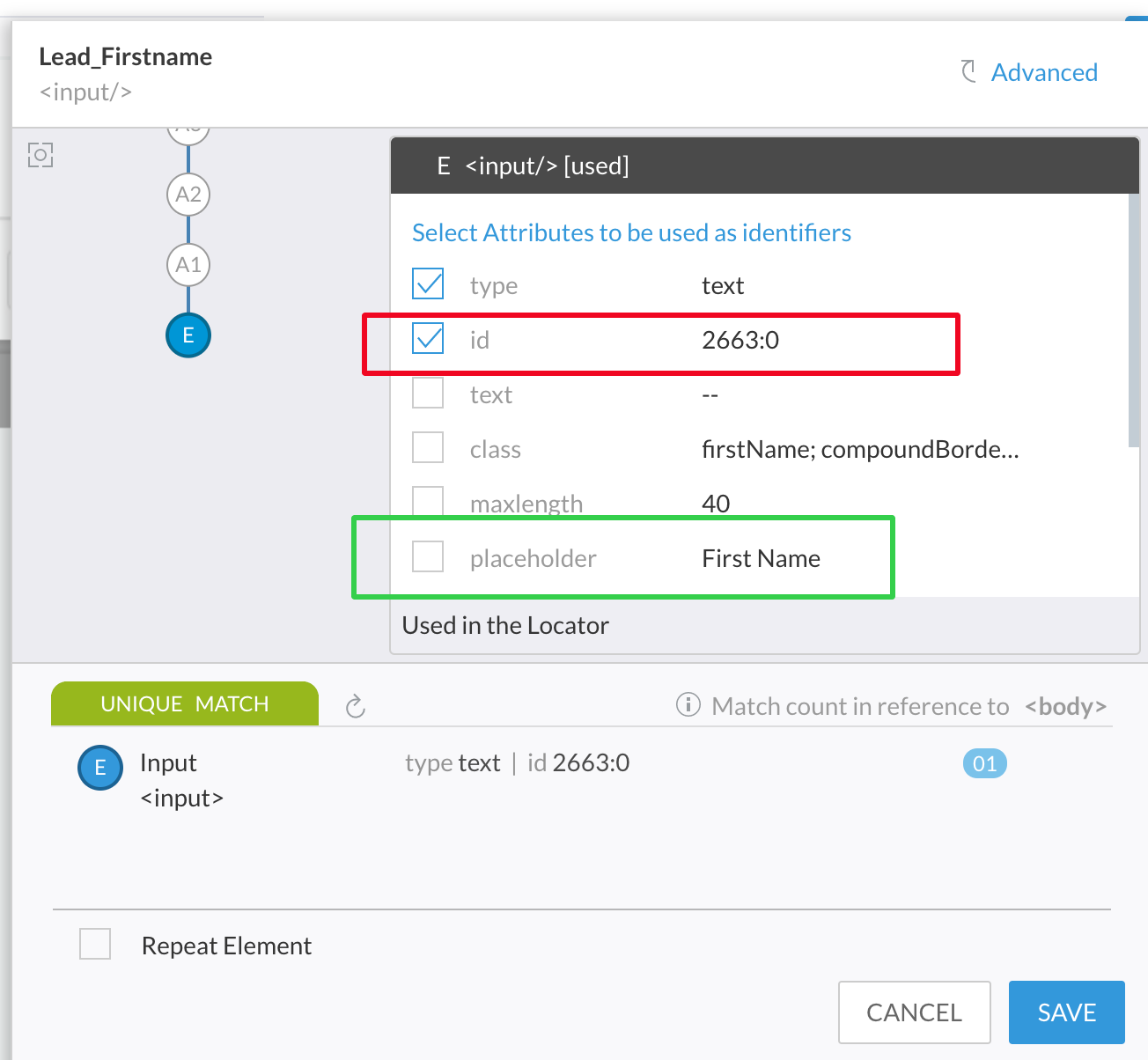
Note, that this random looking id may still work in the first few passes of test execution, but you can't count on something like this longer term. A better option could be placeholder or class as an identification attribute.
Consider another situation below. The "id" attribute here seems to be pointing to the "destination code" for the booking, which can change from time to time as the marketing campaign changes for favorite destination.
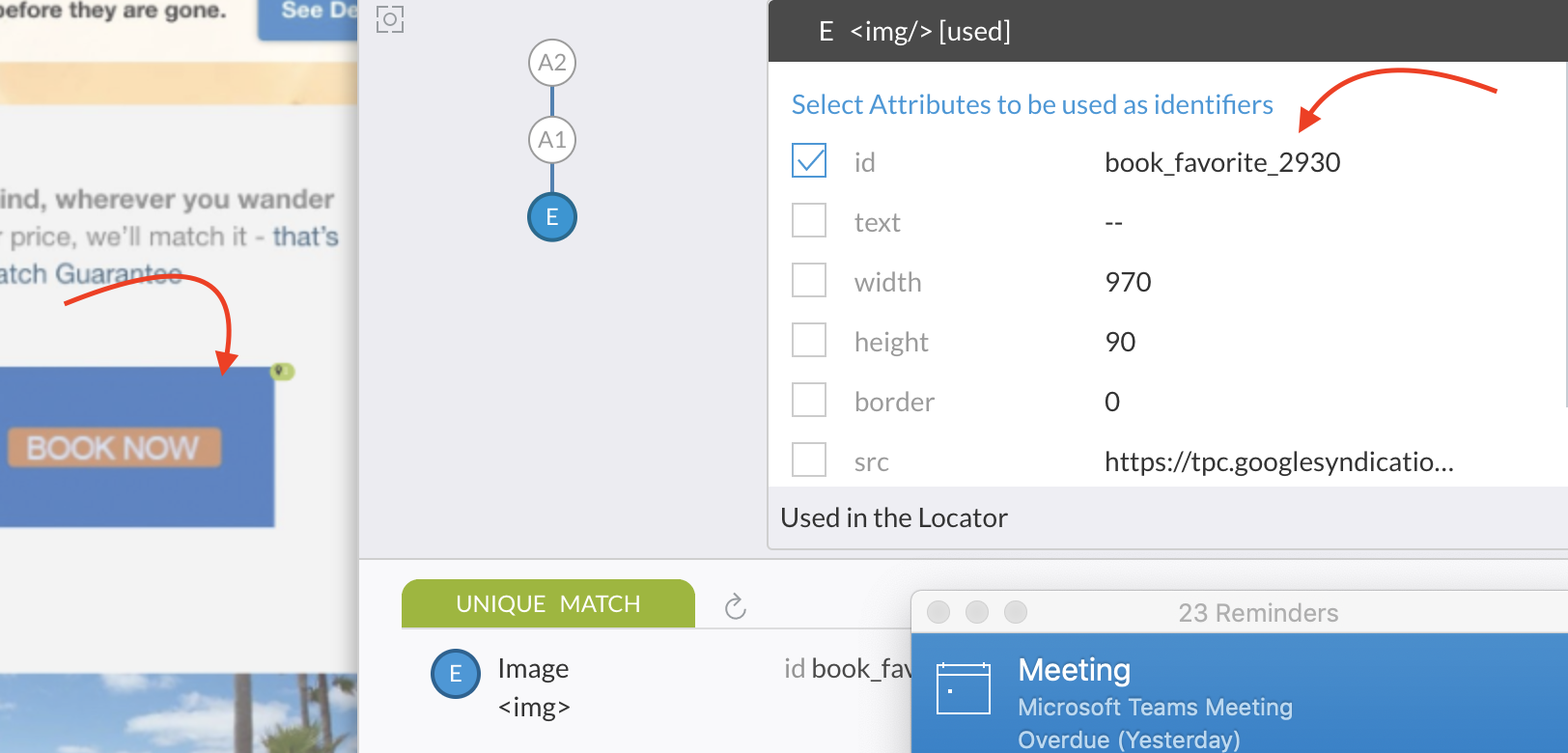 |
Since the initial part of the "id" (book_favorite) seems to be functionally meaningful, let's try to use regular expression to stabilize this value. And as you can see in the image below, uniqueness is still achieved without using the hard-coded numeric portion.
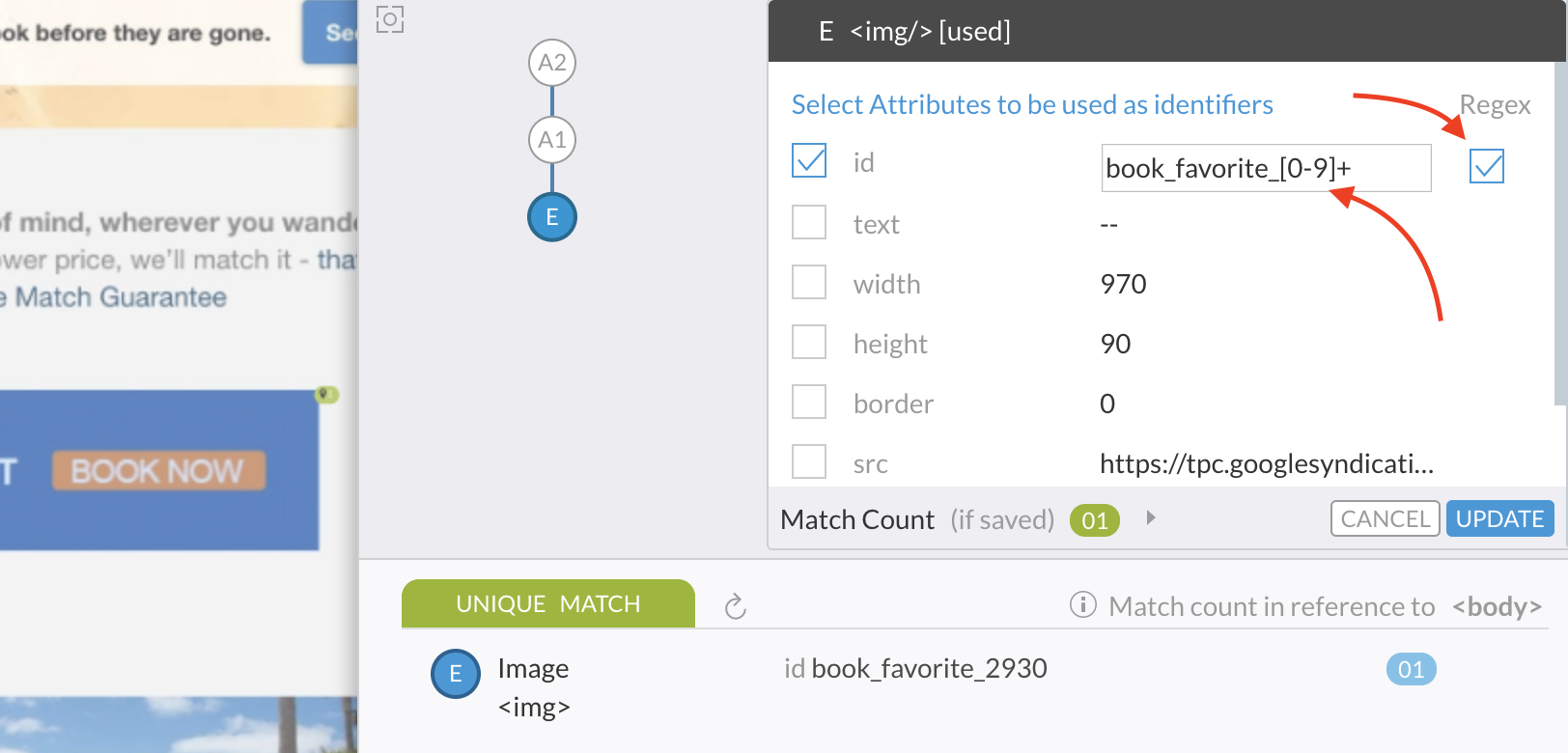 |
See Regular Expression article for additional information on how to use patterns for eliminating variable portion in text strings.
Redundant attributes
It is important to avoid redundancy when you choose attributes. Find the minimal set of attributes that work for unique ID and only utilize the minimal set.
In the example below, you could get uniqueness by just using one of the attributes - class or placeholder. You don't need both.
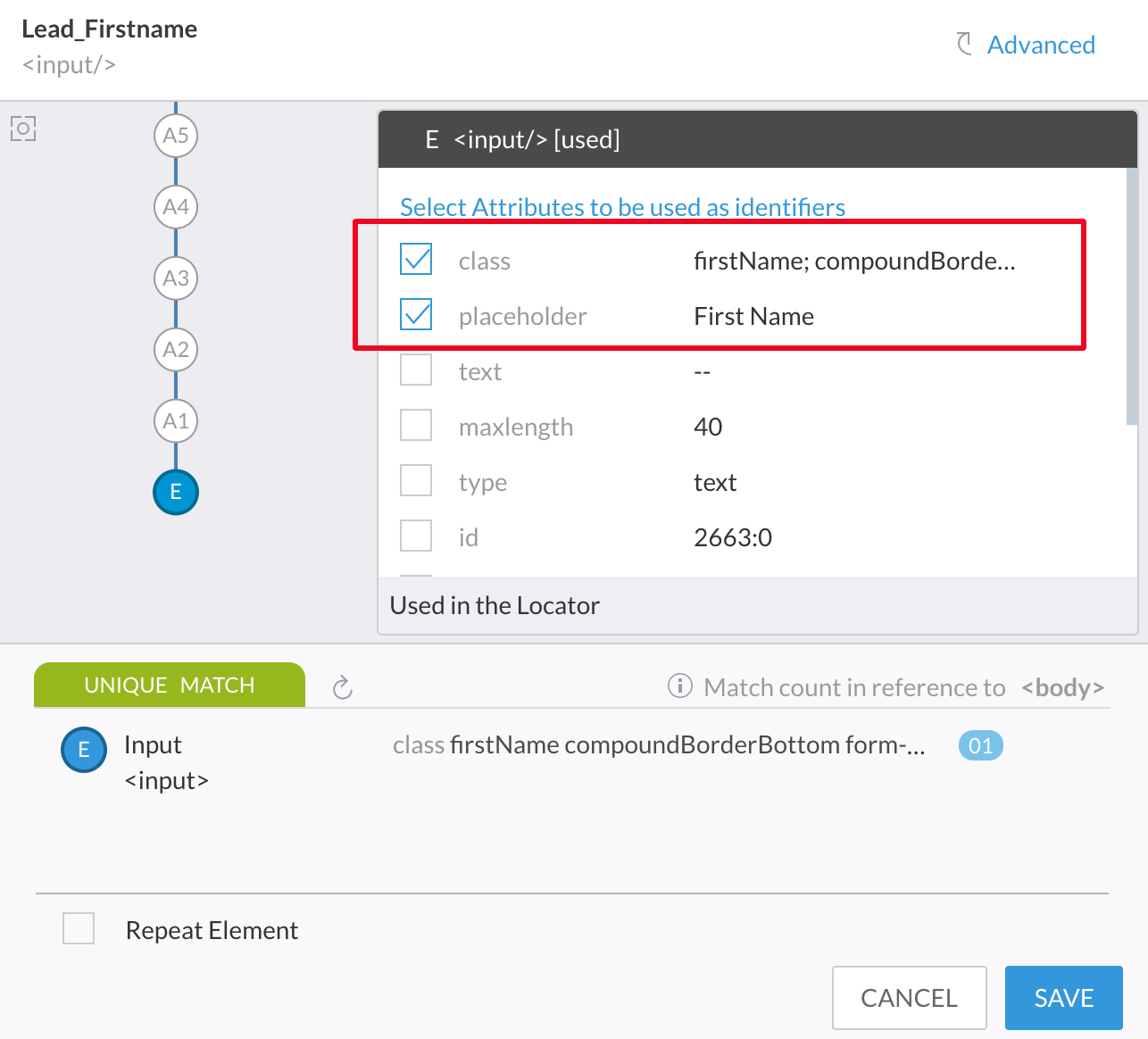
Application change impact is proportionately higher when you use unnecessary, redundant attributes. In the above example, if either "class" or "placeholder text" changes in future, this element may not be recognized during test execution.
Contradicting this very idea, is an example below. In this example, even though just the "text" property is sufficient for unique identification, you might still want to use "class" property for identification.
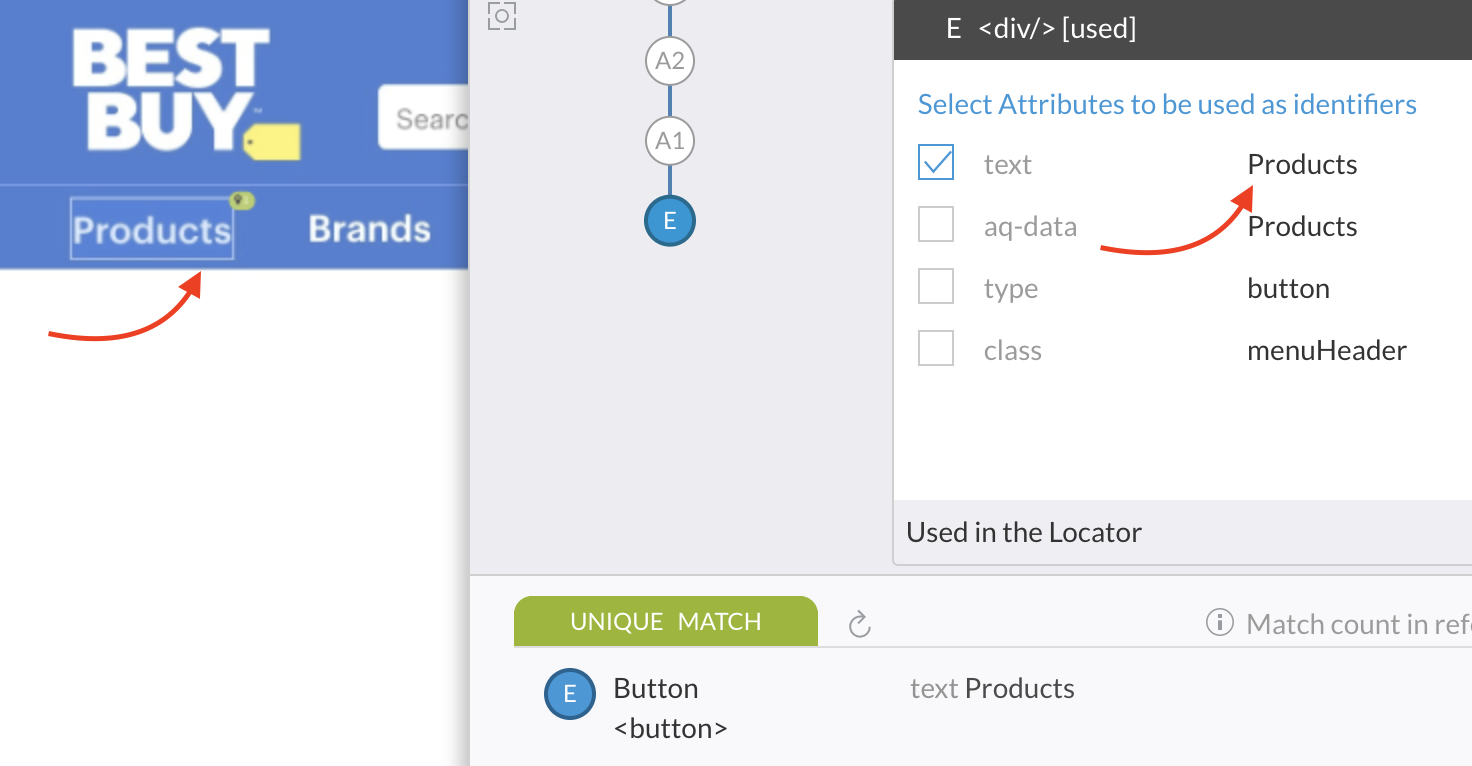 |
Here is the rationale. The text, "Products" is so generic, that some other div element may come up in the application screen in the future with the same text. "text" alone may not significant enough to rely on. Adding "class" property which reads "menuHeader" seems to be very appropriate for the functional significance of this element.
Once again, there is no golden rule. Be judicious with these concepts and apply in your environment as you deem fit.
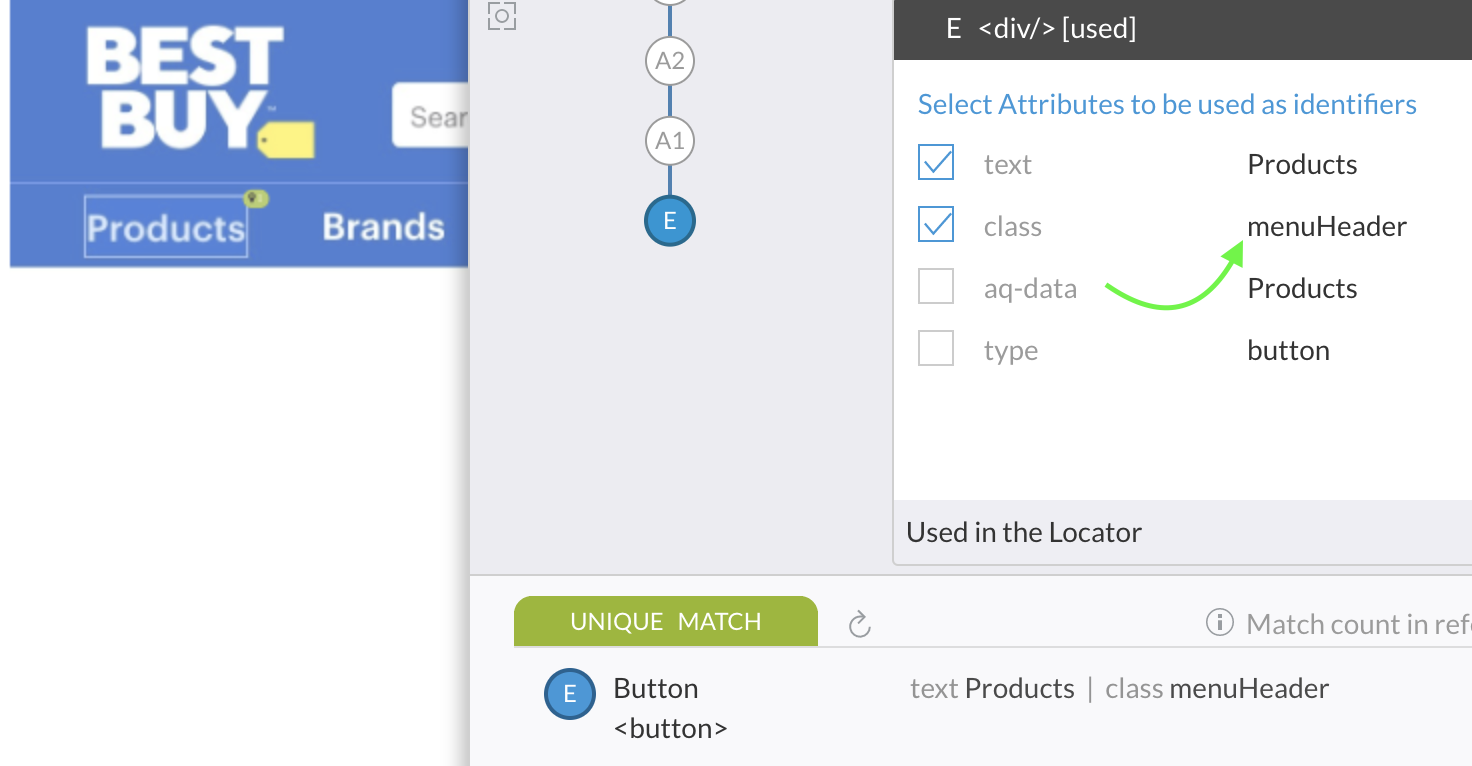 |
Extraneous space characters
If the attribute value includes leading or trailing spaces or some times include multiple consecutive spaces, make effort to stabilize the attribute value. You can utilize Regular expression patterns to eliminate such discrepancies. Multiple or leading/trailing space characters may change in the future and it is hard to troubleshoot as the text value looks pretty similar.
Here is an example on how to apply regular expression in this situation. The regular expression is formulated with a 'space' between the two brackets ([ ]) followed by "+" sign, which indicates 1 or more instances of white space characters.
 |
href attribute and other URL based values
href attribute for anchor element on web pages points to the target of the link click. It may be either pointing to a static URL or a call to a Javascript function. It is not advisable to pick href attribute when pointing to a Javascript function. Example below is not suitable for using in Selector.
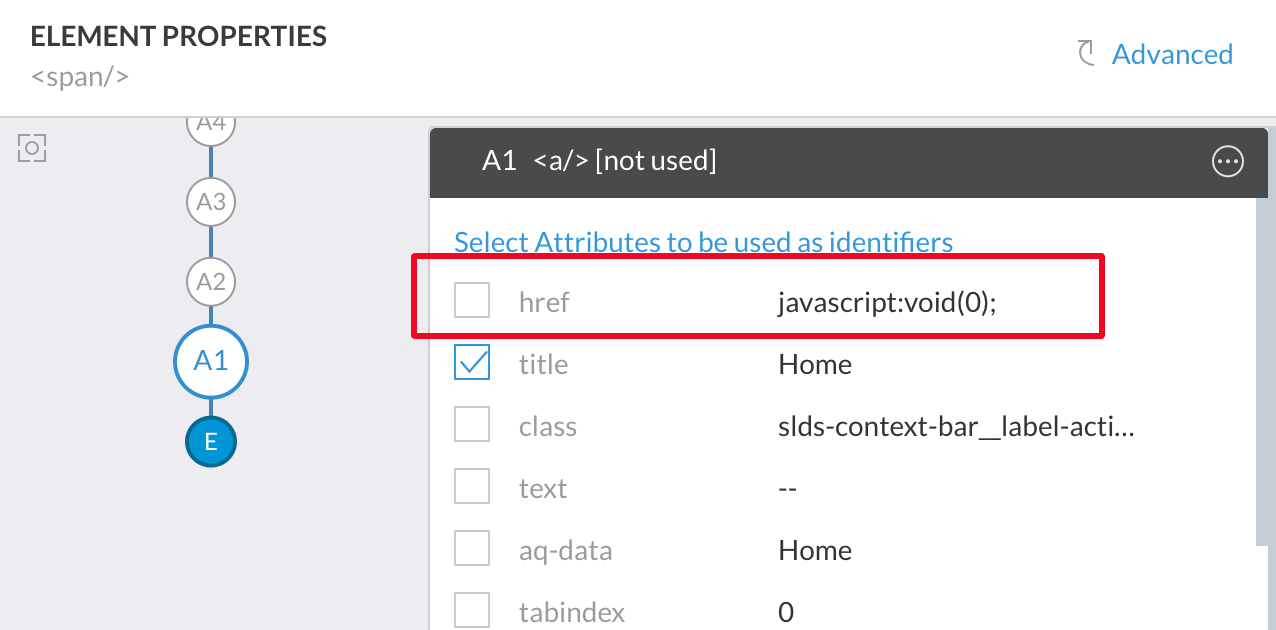
Similarly, when you use any URL based attribute values, make sure that application-environment specific text is not part of the URL. In the example below, your scripts may fail when running in Production or Dev environments as the URL specifically points to test environment. Either avoid such attributes or use regular expression to remove the initial part of the text.
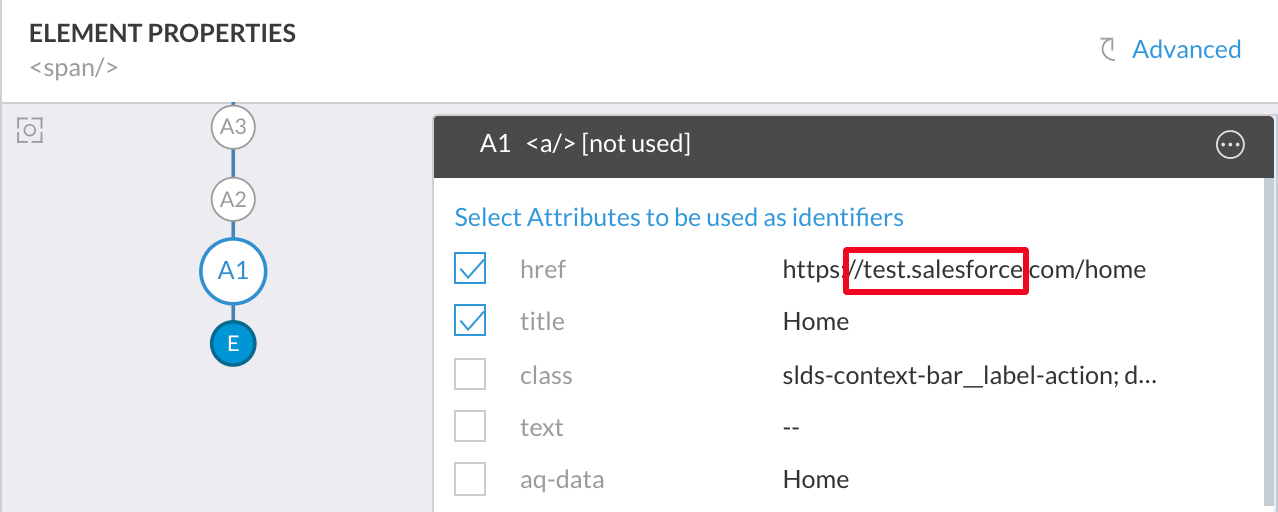
Not all classes may be necessary when selecting class attribute
class attribute in html can point to one or more CSS classes. In accelQ, value for class attribute is a multi-select type. When you select class attribute for the element identification, you can edit the value to just choose a subset of classes that you may find stable.
As a good practice, whenever you select class attribute in the Selector, be sure to review and remove unnecessary classes. If you are achieving uniqueness with a subset of classes with good functional meaning, ignore others.
When working with Angular applications, for example, you can avoid classes such as ng-hide, ng-show etc. These are Angular implementation framework related classes with technical connotation. Do not rely on such classes as they may change with various element interactions during test execution.
In the example below, you can safely remove ng-prestine, ng-valid and medium classes from the value of class. source-account seems more functional and potentially safe to retain in the class value.
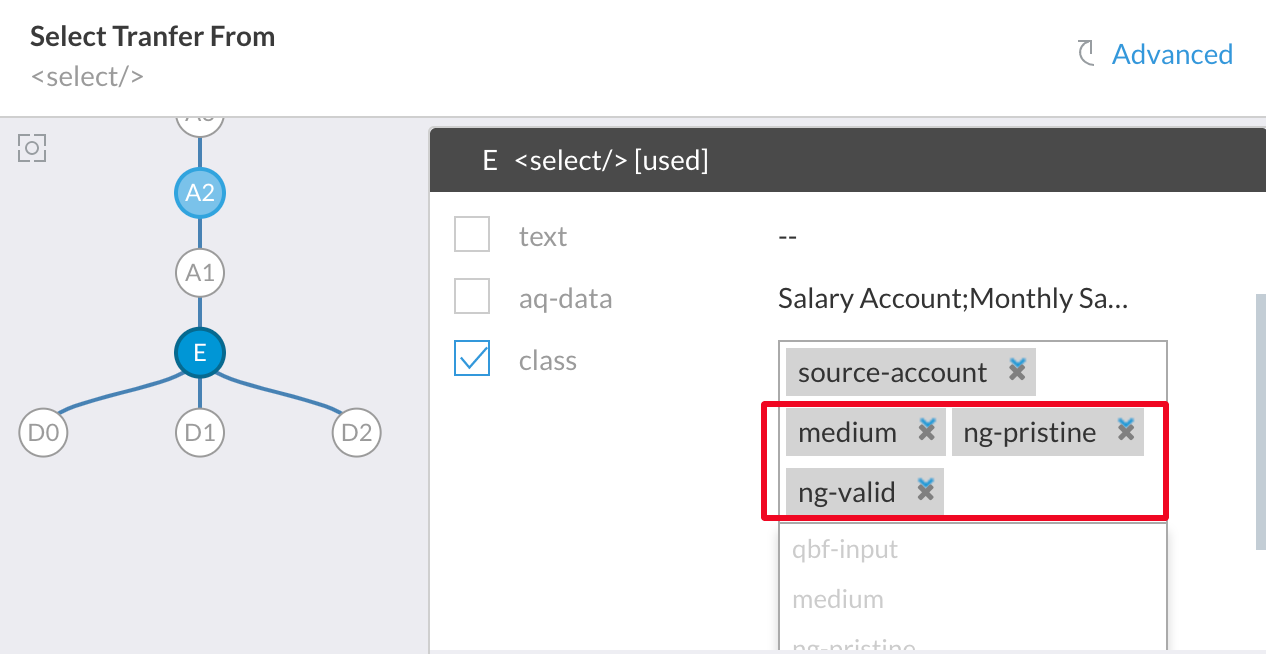
Remember following points:
- Remove any redundant classes from the value of "class" attribute.
- Do not use framework specific classes such as "ng-hide" etc.
- Do not use layout related bootstrap classes such as "col-md-6", "medium" etc.
Be wary of 'text' attribute
For many elements, you may find that text attribute provides good uniqueness. But before deciding to use text attribute, carefully evaluate if this text will remain the same over a period of time and more importantly, under different use cases in your application.
Consider the example below:
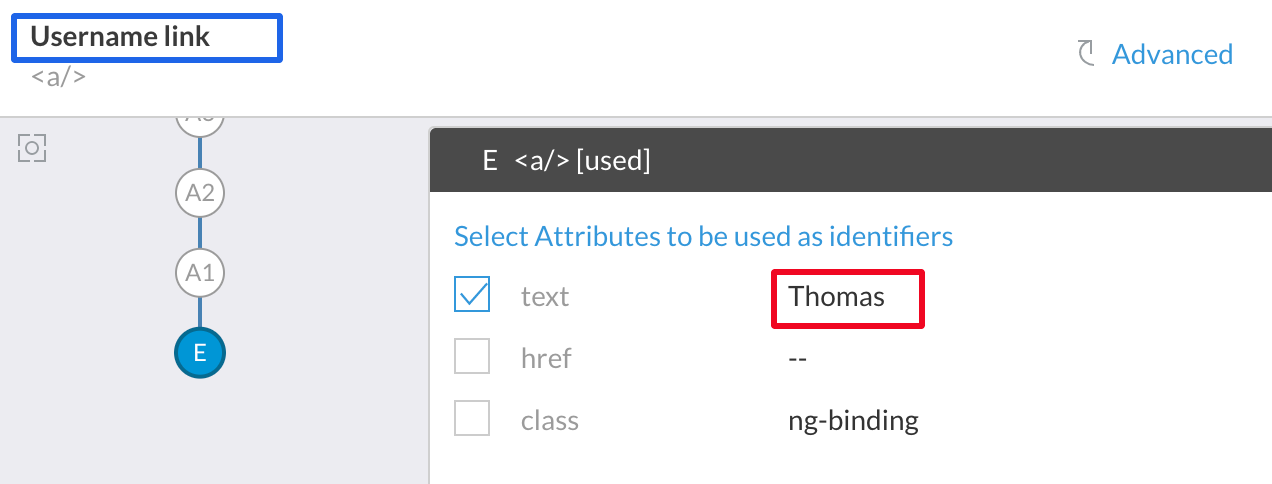
In this case, username link element will recognize perfectly with "text" attribute, as long as you are always running the test as Thomas. But if you run the same test with another customer account, this element will not be identified, as the name of the customer won't match the name that this element is expecting.
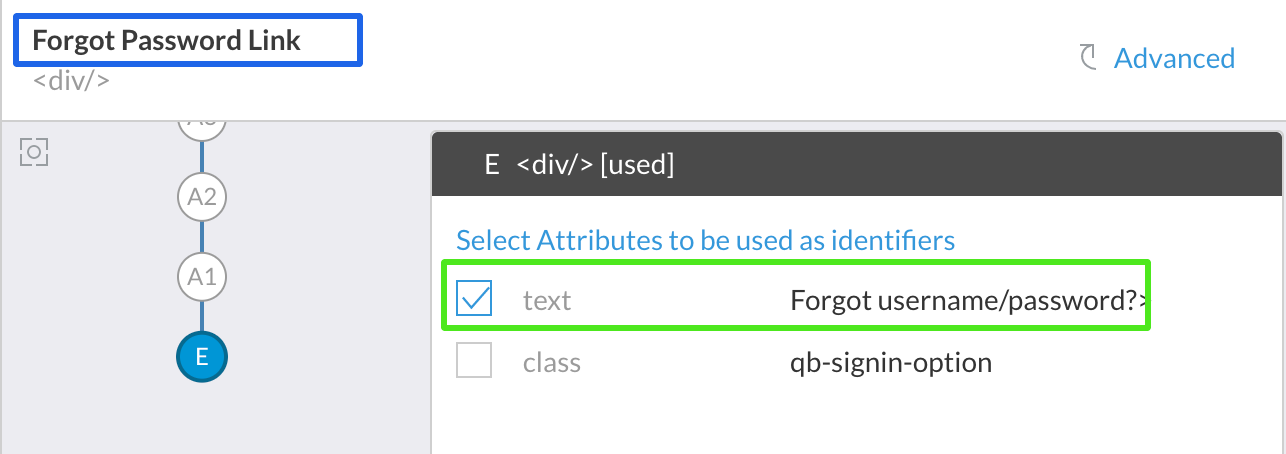
Having said that, there may be perfectly valid cases for using text attribute as in the example below. Forgot Password Link is a link with static text and this text is functional and safe to use.
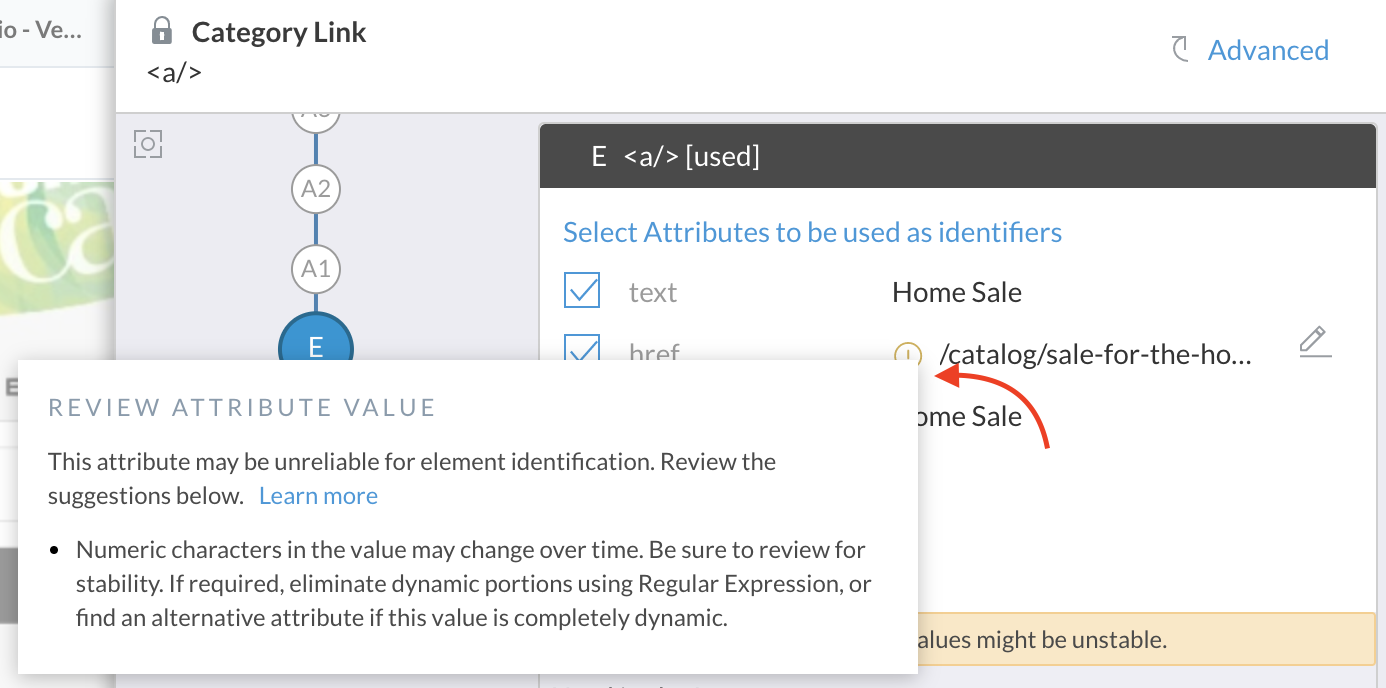
Element-attribute alerts
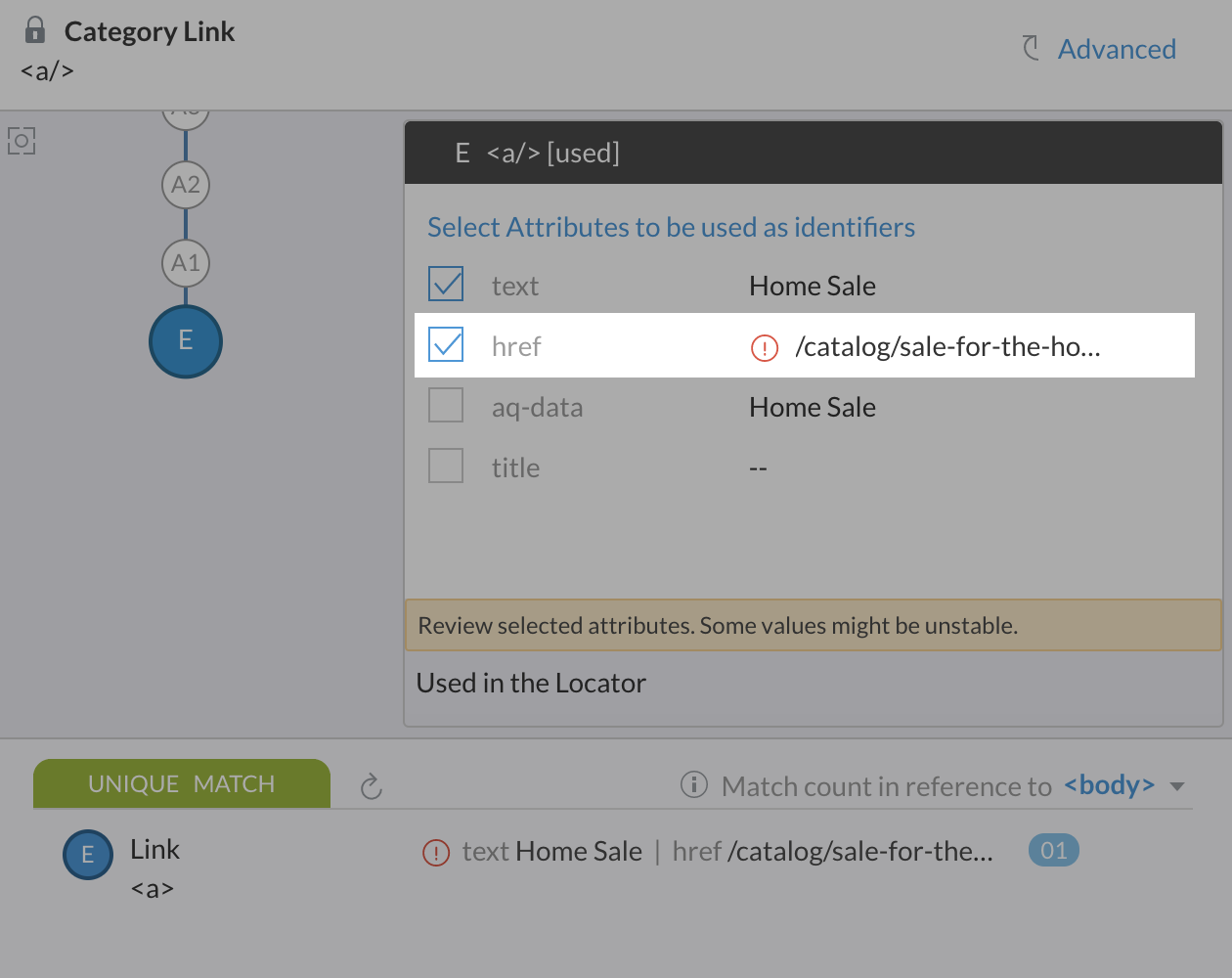
When you are setting up attributes for element identification, ACCELQ analyzes the attribute-value to validate stability. If a particular attribute is found unreliable and selected for locator, an alert pops up to the side of the attribute name.
Clicking on the alert icon provides suggestions and tips to improve the reliability. You may chose to not use such attributes if there are other alternatives.

Comments
0 comments
Please sign in to leave a comment.